VOXReality deployed the pretrained models in three use cases covering sectors that have been highly affected by COVID-19.
DIGITAL AGENT
The Training Assistant provides voice-activated guidance for complex assembly tasks by blending audio-visual contexts for spatially and semantically grounded interaction.
This use case of the VOXReality project focuses on advancing the training experience and widening the scope of the training for factory workers in industrial assembly tasks. The primary focus is on incorporating personalized voice assistance during the assembly training in an Augmented Reality (AR) environment. The AR Training use case, integrates ASR and ARTA into the Hololight Space Assembly software, an experimental platform originally designed for linear industrial assembly training.
The software was customized to support open-ended learning environments, allowing users greater flexibility in task execution, aligning with constructivist learning principles that emphasize problem-solving and engagement over rigid, prescribed sequences. The AR Training use case includes both a voice-controlled “Voxy Mode,” leveraging ARTA and ASR for voice-driven interactions, and a traditional Graphical User Interface (GUI) mode relying on hand menus.
The Dialogue Agent (Voxy) forms a feedback loop with the environment, monitoring user actions, anticipating their needs, providing context-aware support (hints, video documentation), and executing actions like skipping or undoing steps via voice commands.
VIRTUAL CONFERENCING
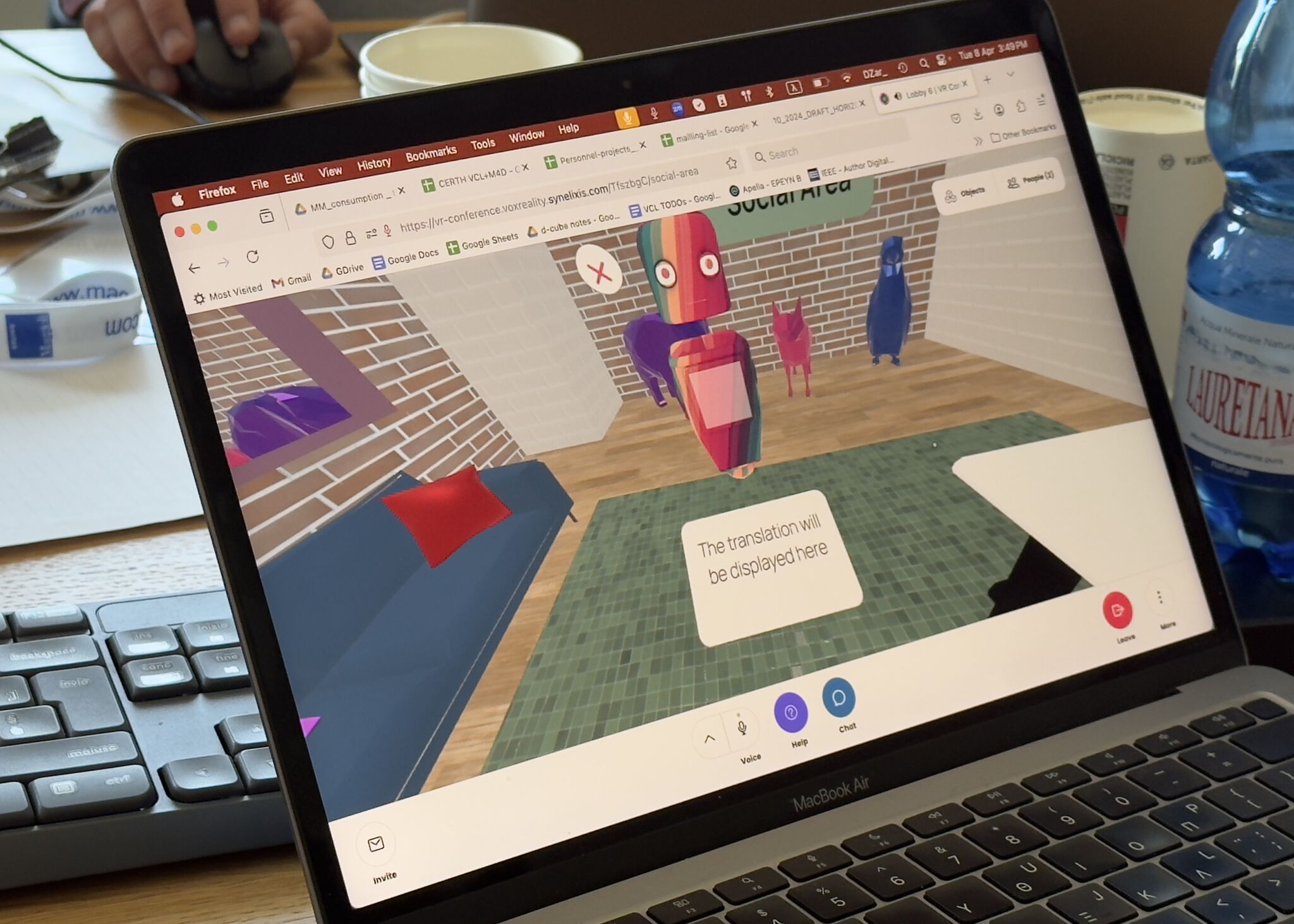
The VR Conference enhances virtual events by supporting real-time multilingual communication and assisting attendees with contextually aware navigation.
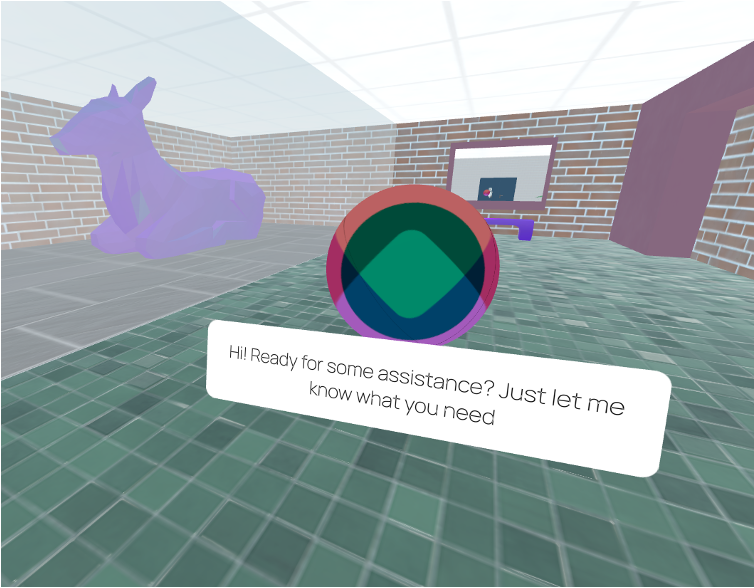
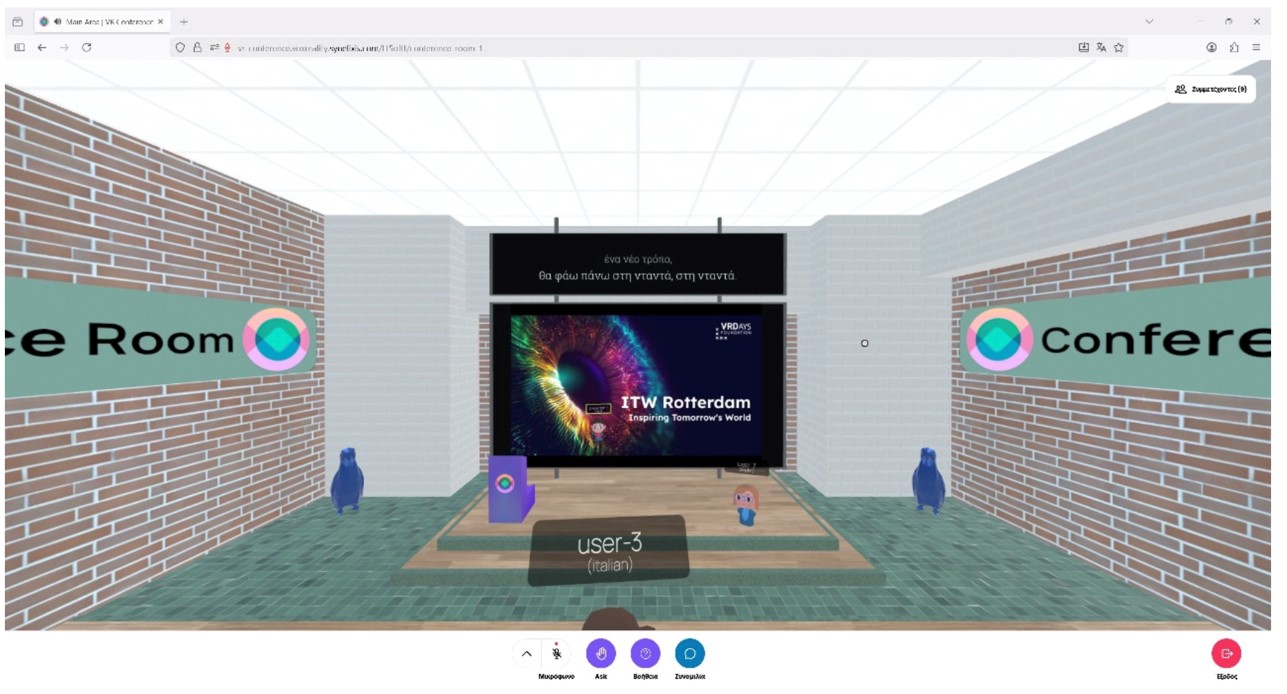
The VR Conferencing case offers a virtual personal assistant that provides conference visitors with venue navigation, programme advice, and instant translation in six languages. The virtual personal assistant will allow seamless venue navigation and multilingual business and social interactions. The main objective is to provide a comprehensive virtual conference environment simulating a professional setting (Lobby, Trade Shows, Business, Social, and Conference Rooms).
The system employs a powerful WebSocket-based translation architecture that performs efficient, single-instance transcription and translation per language,
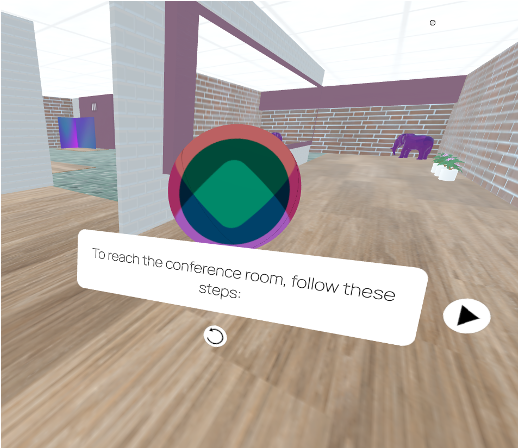
regardless of listener count, minimizing latency and resource use. The Virtual Agent uses a Dijkstra shortest-path algorithm combined with an LLM (NaVQA) to generate and deliver fluent, natural-language navigation instructions and visual cues.
The dialogue agent tailored specifically for VR conferences to provide an all-in-one assistant experience.
The agent offers navigation assistance, answers questions about the event program, and provides information about the trade show. Users can ask how to reach a particular room, and the agent not only responds in natural language but also provides visual cues that guide them directly to their destination. This integration of verbal and visual guidance makes navigation in VR environments feel natural and intuitive, creating a more enjoyable and accessible experience.
THEATRE
The AR Theatre elevates live performance by delivering personalized, translated captions and AR Visual Effects (VFX) directly to the audience via XR headsets.
The Augmented Theatre use case introduces AR technologies to theatre audiences. Using AR equipment (glasses) theatregoers experience two different components of AR elements during a theatrical performance: voice activated, AI generated sub or surtitles and visual effects. As part of its Augmented Theatre pilot, the Athens Epidaurus Festival, with the support of Maggioli Group, explored the use of augmented reality (AR) technology in theatre to develop the 15-minute AR live performance Hippolytus (in the Arms of Aphrodite), directed by Yolanda Markopoulou. The performance, which included captions through
AR glasses and visual effects tested the technologies developed in VOXReality merging them with stage action, sound, and digital scenography into one immersive storytelling experience.
Hippolytus (in the Arms of Aphrodite) aimed to explore intimacy and presence in XR theatre: two actors performed for two spectators wearing Magic Leap AR headsets, dissolving the distance between the audience and the stage, the physical and digital dimensions. Translations are pre-generated offline and human-proofread to ensure high literary quality and reduce live latency. The system’s central control server orchestrates the experience, triggering VFX based on both verbal cues (caption matches) and visual cues (VL detection of stage events like actor entrances/exits), using a determined VFX plan.